netail.net
自作フリーソフトや,ゲームに関する雑記を公開してます.
日記はソフトウェア工学の論文ネタが中心です.
最近のお知らせ (古いものはこちら)
2004-05-01 古い日記からの変換データ [長年日記] ▲
_ 論文 ▲
論文の大量消化を進行中.
Mark Harman, Lin Hu, Malcolm Munro, Xingyuan Zhang, David Binkley, Sebastian Danicic, Lahcen Ouarbya and Dave (Mohammed) Daoudi:Syntax-Directed Amorphous Slicing.Journal of Automated Software Engineering,11(1): pp.27-61, 2004.
Amorphous slicing は,構文の簡略化を含んだスライシング手法.スライス計算の結果,if 文の条件式が必ず false になるとか,関数の引数が使われないとかいったことが判明したら,if文を丸ごと削除したり,引数を減らした関数定義を作ったりして構文木を保存しない状態でスライス結果を出力する.なので,用途としてはプログラムの簡略化などになる.
計算時間や空間コストはやっぱり n の自乗.500 行のプログラムで,最善で約1秒,最悪で約2分とかいうくらいに極端な差が出るようで,そんなに大規模なシステムに適用できるわけではない.
AST 変換なアプローチを取っていて,依存グラフ構築のアプローチよりも局所的な変換ルールはシンプルになる点が有利らしい.SDG アプローチ側は依存関係の整理には向いている,というように比較が入っているので,この種の比較を引用するには便利そう.
_ 論文 ▲
Lahcen Ouarbya, Sebastian Danicic, Dave (Mohammed) Daoudi, Mark Harman and Chris Fox:A Denotational Interprocedural Program Slicer.9th IEEE Working Conference on Reverse Engineering (WCRE 2002). 28 October - 1 November, 2002. Richmond, Virginia, USA, Pages 181 - 189.
コールグラフなどの構築ではなく,AST の変換によってプログラムスライスを計算しようという方法.
V が注目している変数(スライス基点)だとして,Slice(if B then S1 else S2, V) はif B then Slice(S1, V) else Slice(S2, V) となる,といったような処理を,各時点での変数の最新値を持ちながら計算していく.グラフ構築→ traverse という順序のかわりにいきなり計算しているだけのようにも見えるが.
式における SideEffect のあるなしを考慮している点はえらいかもしれない.関連研究として CodeSurfer を挙げているわりにほとんど比較がないので,この手法の利点がよく分からない.
_ 論文 ▲
Mark Harman, Rob Hierons, Chris Fox, Sebastian Danicic and John Howroyd:Pre/Post Conditioned Slicing.17th IEEE International Conference on Software Maintenance (ICSM 2001). Florence, Italy, November 6th-10th, 2001. Pages 138-147.
Conditioned slicing を応用して,Pre condition からの forward conditioning (Pre condition が成立している状態で実行されるプログラム文)と Post condition の否定からの backward conditioning(Post condition が成立しない状態へ寄与するプログラム文)の共通部分を抽出することで,「pre condition が成り立っているのに post condition が失敗する可能性のある(バグの可能性がある)」文集合を抽出しようというもの.
基本は conditioned slicing で,symblic state expression(システムがとりうる状態)を各プログラム文に対して伝播させていく.
pre/post conditioned slicing が空になるようにコンポーネント抽出を行う,あるいは verification 用途に使う,といったことが主目的となる.assert の積極的な定義と合わせて使えば強力なツールとなりうる?フィールド値などの条件定義をうまく与えないと他の手続きからの影響を除去しきれないかもしれないが.とはいえ,スライス系の研究の中ではかなり面白い部類に思える.
_ 論文 ▲
Mark Harman, Nicolas Gold, Rob Hierons, Dave Binkley:Code Extraction Algorithms which Unify Slicing and Concept Assignment.9th IEEE Working Conference on Reverse Engineering (WCRE 2002). 28 October - 1 November, 2002. Richmond, Virginia, USA Pages 11 - 21.
プログラムスライシングと Concept Assignment を併用することでプログラムを分解しようという試み.
Concept Assignment というのは,プログラム文の集合と Concept を対応付けるというものらしい.これに,各 Concept のプログラム文からスライスを計算することで Concept に関連したプログラム文を得る.また,concept の最終結果となるような変数 (Principal Variable) を最後に使ったプログラム文を重視して,それを基点に計算したスライスに含まれているところを重要度が高い,と分類する.(0から1の実数と定義しているが, 実際には 0と1だけを使っている)
そして,各 concept の Principal Variable の最後の利用場所から計算したスライスの共通部分の大きさによって concept 間の依存性を解析する.で,concept 間の関係を重み付きグラフとして出力する.
いちおうケーススタディとして小さなプログラムを相手に計算を行って,どの文が重要か,というところは計算している.しかし,concept 間の関係については,得られた結果をどう使うか,という問題がある,concept 同士の依存関係がわかっても,concept 同士の相互の関係がどういうものか分かるというわけではない,としている.
全体としては,こんなので効果があるのかなぁ,という落ち着きのない感じがする.アルゴリズムは丁寧に書いてあるのだが,スライシングや concept assignment の手法についてほとんど言及がないせいかもしれない.
_ 論文 ▲
David Binkley, Mark Harman:A Survey of Empirical Results on Program Slicing.
プログラムスライシングの survey.といっても,ほとんどの論文は読んだことがあったのであまり意味がなかったが,どのデータがどの論文から来たか,というのが分かるという点で便利な論文.
静的スライスはだいたいプログラムを3割くらいに減らせる,とか CodeSurfer はシステム依存グラフを事前計算してしまうのでスライス計算速度自体は早い,とか,dataflow based slicing は10万行ぐらいのプログラムでも相手にできる,とか.
スライシングの方法としてデータフローから計算するタイプとプログラム依存グラフを構築する方法と大きく区別できて,それにサポート技術として context-sensitivity やsummary edge やグラフの集約があるため,条件を対等にして比較することが難しい,と言っている.スライスの応用に関しても,たとえばプログラム理解であれば,単なる静的スライスを使う方法とPre/Post Conditioned Slicing などを使う方法ではだいぶ違った結果になるだろう,としている.
全体としては,プログラムスライシング技術が実用的であるといえるだけの証拠はある,というふうに締め括っている.ちょっと胡散臭い気もするが.何に使うか,という話から始まらないとどの目的にはどのスライス手法が有効,みたいな議論になっていかないので,まだまだ怪しい気がする.
_ 論文 ▲
David Larochelle, David Evans:Statically Detecting Likely Buffer Overflow Vulnerabilities.
LCLint でのバッファオーバーフロー検出機能に関する話.配列ごとに安全に読み書きできる範囲をmaxSet, minSet, maxRead, minRead として保持して,その範囲外になる可能性がある読み書きの文に対して警告メッセージを出す,というもの.
検出方法として,手続き内部で制約を伝播させていく以外にfor ループから,*buf++ のような定型句を見つけてindex や buf がどの範囲を指しうるかを検出する.こんなのでうまくいくのか,という気もするのだが,けっこううまくいくらしい.
C言語だと書き方がある程度決まりきっているからかもしれないが,実例として wu-ftpd や BIND などが上がっていて,きちんと実験しているツールなので,説得力もある.
_ 論文 ▲
David Evans, John Guttag, James Horning, and Yang Meng Tan:LCLint: A Tool for Using Specifications to Check Code.Proceedings of the 2nd ACM SIGSOFT symposium on Foundations of software engineering.pp.87-96, New Orleans, Louisiana, United States, 1994.
論文というよりは LCLint の説明ドキュメントか.「こういう spec を書くとこういうエラーが検出できます」という見本集のような印象.
_ 論文 ▲
L.C.Briand, Y.Labiche, J.Leduc:Towards the Reverse Engineering of UML Sequence Diagramsfor Distributed, Real-Time Java software.Carleton University, Technical Report SCE-04-04, April 2004.
AspectJ Users ML で,「loop や if 文を検出するpointcut がほしい」と言っていた研究者の論文.
やってることは実行履歴からのシーケンス図の復元.contribution としては復元方法についてきちんと仕様として明記したこと.他の手法は形式的な記述が少なく詳細も十分でない,らしい.
スレッドIDとどのメソッドが実行されているか,とどのループや if 文が実行されているか,という情報を合わせて使って,プログラムの動作を追跡する.
分散環境についてもきちんと考えていて,RMI は呼び出し時にブロックするのでノード(JVM)ごとに local clock を1個だけ保持しておけばRMI に関しては呼び出し側の node ID + client thread ID を覚えておけば remote 側の呼び出し履歴と対応が取れる,ときちんと説明しているあたりはえらい.# 非同期な呼び出しは想定していないとも言うが…….
スレッド間の同期方法については,Runnable.start および run の呼び出しの監視が基本.データ構造を介した非同期な情報のやりとりについては,(開発者は組織などの標準的情報を持っているはずなので)どのクラスがスレッド間の情報転送に使われるかを設定ファイルとして用意するらしい.何か参考になるかと期待していたのに,がっかり.
実現方法について,AspectJ のソースコード風に表現しているところが親切.「AspectJ の future release では loop や if を 検出する pointcut が入る可能性がある」と書いてるあたりはいい加減だが,東工大の千葉先生のグループの Josh とかを使って自前で実装するぶんにはできるだろうし.
一通り目を通してみて,実際にはシーケンス図作ってないなーと思ったら論文タイトルの "Towards" に気づいてがっかり.ステレオタイプの "boundary" とか "control" とかまで書いてある図が一つあって「こんなのまで識別してるのか!」と期待してしまったが,単に設計書からのコピーだった.うーむ.
2004-05-02 古い日記からの変換データ [長年日記] ▲
2004-05-03 古い日記からの変換データ [長年日記] ▲
_ 読書 ▲
「パズルの国のアリス II」読了.
今度は鏡の国のアリスがベースになった話で,ハンプティ・ダンプティによるパラドクスの話と様相論理を用いたパズルが主体.
こういうパズルが普通に(難易度の高いものは手間がかかるが)解けるようになった時点で,大学とかで受けた一部の講義がそれなりに効果を発揮しているのかもしれない.
_ [論文]モデルと実装の対応 ▲
Rainer Koschke, Daniel Simon:Hierarchical Reflexion Models.Proceedings of 10th Working Conference on Reverse Engineering (WCRE 2003), pp.36-45,13-16 November 2003, Victoria, Canada.
reflexion model というアーキテクチャと実装の対応付けを行う手法をきちんと階層化した構造に対して適用可能にしたもの.
最初に,モデルとして,モデル要素とその依存関係を適当に設定する.次に,ソースコードの各要素からモデル要素へのマッピングを決めて,モデルに含まれていないのにソースコードにある依存関係,モデルには含まれているのにソースコードにはない依存関係がないかどうかを調べる.これらの依存関係が存在する場合はマッピングがおかしい(モデルと実装が食い違っている)のでマッピングを修正していって正しいモデルを得る,ということになる.
Reflexion model 自体は G. C. Murphy らによって提案されたもので,この論文は階層化に関する拡張で階層化された要素間でのマッピングの関係を整理しているところが新規性か.大規模のソースコードに対するケーススタディを行っているあたりがえらい.
最初のモデル構築の部分は人手に頼る部分は大きいが,モデルと実装のギャップを調べるという技術としては有用であるように思える.
_ 論文 ▲
移動中に読んだ論文の整理.
R.M. Hierons, M. Harman, and H. Singh:Automatically Generating information from a Z specification to support the Classification Tree Method.
Z 言語で記述された仕様の事前条件などの predicates から,いわゆる事前条件と,入力の値域の分割とを表現した述語を区別する.この区分ができると,少なくとも事前条件を満たした上で,入力の値域に関する述語それぞれをTRUE/FALSE とするような Calssification Tree が構築でき,テストケースの自動生成につながる,というもの.
アプローチとしては面白い.
_ 論文 ▲
Bixin Li:Analyzing Information-Flow in Java Program Based on Slicing Technique.Software Engineering Notes Vol.27, No.5, pp.98-103, Sep. 2002.
プログラムスライシングを使って,コンポーネント間を流れている情報量や結合度の計算などをやってみよう,というもの.前提として正確なスライシングができることなどが入っていて,また提案している要素の妥当性の説明が弱い気がする.
_ 論文 ▲
Jens Krinke:Evaluating Context-Sensitive Slicing and Chopping.ICSM 2002.
現在のコールスタック状態を意識しながらスライス計算を実行するとき,その call string の長さを定数 k で固定するとどうなるか,というのをk を変化させながら実験している.呼び出し関係のグラフのうちループを1頂点に縮約したFolded Context Slicing 手法ならSummary Edge を使って計算した手法と比べてもそんなに悪くない結果が出ている.
PDG 構築コストが高いので Summary Edge 計算のコストが無視されている,というところが微妙だったりする.
この比較結果は面白いところで,PDG 構築以外の場所でも役立ちそうな気がする.
_ 論文 ▲
Gagan Agrawal, Liang Guo:Evaluating Explicitly Context-Sensitive Program Slicing.PASTE'01, pp.6-12, June 18-19, 2001.
プログラムスライスの計算時に,その時点でのコールスタックの中身がどうなっているかを計算しながら実行することでCall String (コールスタックの中身の表現)ごとに同じ手続きでも異なるスライス結果を持つように設定する.その結果,スライスサイズが減少する.計算時間については,極端に増えるとかいうことはなく,むしろスライスサイズの変化によっては計算時間が減少することもあるらしい.
_ 論文 ▲
Donglin Liang, Mary Jean Harrold:Slicing Objects Using System Dependence Graph.ICSM 1998, pp.358-367.
オブジェクト指向言語のためのスライシングの話.オブジェクトのメンバー構造をツリー状で表現する(メンバーがオブジェクトなら,さらに下も必要に応じて展開する).フィールドはやっぱりパラメータとして渡されて,パラメータがオブジェクトなら,オブジェクトのメンバーへのアクセスはオブジェクト変数からのデータ依存を持つ,という形になる.
インタフェースの解析については参照される変数集合(GREF)と変更される変数集合(GMOD)を解析する手法が次の文献に出ているらしい.W. Landi, B.G. Ryder, and S. Zhang:Interprocedural modification side effect analysiswith pointer aliasing. Proceedings of SIGPLAN'93 Conference on Programming Language Design and Implementation,pp.56-67, June 1993.
2004-05-05 古い日記からの変換データ [長年日記] ▲
_ Calendar ▲
hyCalendar が,またムックに収録されるらしい.WindowsXP World Vol.4
収録されるようになって,世の中には色々な雑誌があるものだ,と実感.っていうか,収録雑誌のうち,ちゃんと知っていたのはアスキーくらいなのだが…….
そのほか,要望を送ってきてくださった方がいて,その中で妥当そうなものは「日付の枠色指定」「大安など日付情報の付加」というところ.日付情報は誰が作るか問題があって嫌なのだが,この手の日付情報を与える何かと連動するのは面白いかもしれない.
時刻管理などは六週七曜なカレンダーの限界でちょっと難しい.というか,物理的に情報が表示しきれない可能性がある.別ビューを用意するのも面倒だし.
また,予定が多いときに隣の枠まではみ出してよいかどうか,という設定は描画順序とクリッピングの問題があるので悩ましい.
わりと実装上の制限をびしびしと受けている感じではある.
2004-05-07 古い日記からの変換データ [長年日記] ▲
_ レガシーアプリケーションの保守の話と,http://www-6.ibm.com/jp/developerworks/java/040507/j_j-aopsc2.html ▲
Javassist の話.http://www-6.ibm.com/jp/developerworks/java/040507/j_j-dyn0302.html
IBM ががんばってるのだけは良く分かる.
_ bun45 ▲
bun45.let.osaka-u.ac.jp が文学部内部ネットワークに切り離された.……ので,学内からも他学部だとアクセスできないのでCGI 等の保守がまったく不可能になってしまった.
www.let.osaka-u.ac.jp あたりがゲートウェイも兼ねているのかな?という予想があるのでssh アカウントくれくれと管理者の人にお願いするメールを送ってみた.ページも www.let に移動しないといけないし.
本当は誰かのコネを使ってroot になるくらいの覚悟で活動すればいいんだろうけど,それは避けたいし.
それにしても,bun45.let.osaka-u.ac.jp へのリンクを既に広めてしまっているので移転するのをさっさとやらないと問題だ.
_ 読書 ▲
Anne McCaffrey, "Pegasus In Space" を読み始めた.「ペガサスで飛ぶ」と「銀の髪のローワン」をつなぐ間の話でなぜか未訳.時間的には「ペガサスで飛ぶ」の直後.Concluding her magnificent Pegasus Series と書いてあるからこれでシリーズがひとまず終わり.
読んでて一番厳しいのは人名のスペルだったりして.Rhyssa,Peter や John のようにすぐ分かる人はいいとしても,Tirla(ティーラ)とSascha(サーシャ)あたりは微妙に見落としそうだった.
技術論文とは違って会話が多いので,読むのが遅い.
_ 論文 ▲
J. Rilling, A. Seffah, C. Bouthier:The CONCEPT Project - Applying Source Code Analysisto Reduce Information Complexity of Static and Dynamic Visualization Techniques.In 1st International Workshop on Visualizing Software for Understanding and Analysis, 2002.
ソースコードを理解するための環境を作ろう,という研究.ソースコードから図を構成することで全体の様相を把握して,静的スライス,動的スライスで注目したい部分だけを抽出するというタイプ.
図の構成には,アイテムを矩形で表現して全体の大きな矩形を埋めていく Treemap と,注目したノードの周辺を大きく,遠くなるほど小さく描画するHyperbolic tree,プログラムスライスだけをハイライト表示するシーケンス図など.詳細を省き,あくまで概略をつかむための図という位置づけのようで,focus を一箇所に絞るのが動的スライスだ,と言っている.
動的スライスについては,実行履歴上で,「ある注目したい機能に関連した部分」とそうでない部分で同じ関数を呼び出している場合もある,そんなときは関係ない場所から呼ばれたことは無視したりできたらいい,ということも言っている.
2002年の論文なので,現在だともう少し研究が進んでいる可能性が高い.どこかに出ているかな?
_ 論文 ▲
Dirk Heuzeroth, Thomas Holl, Welf Lowe:Combining Static and Dynamic Analyses to Detect Interaction Patterns.IDPT 2002, Pasadena, CA.
ソースコードからデザインパターンなどを検出しようという試み.Observer パターンであれば Observer と Subject の候補がきちんと addListener に相当するメソッドなどを持っているかどうか,ということを検査する.お互いのメソッド呼び出し関係がデザインパターンの規則を満たしているかどうか,などが基準となるよう.
で,静的解析結果で得られた候補から,さらに動的解析を行って(テストケースを実行して)実際の結果を出すらしい.
だから,・ある程度きちんとデザインパターンに則っていること,・十分な数のテストケースが容易されていること,などが満たされないと検出は難しそう.
手を抜いて removeListener がない(登録しても解除不可)とか類似したコードを書いていても検出されない場合も出てきそう.(もちろん,テストケースで,インタラクションがなければ 検出できない).厳しい分,false positive はなさそうだが.
モデル図上で「ここはイベントリスナーで接続」とか「ここは delegate で」とか分かるのであればそれなりにうれしいかもしれない.
_ 論文 ▲
William Landi, Barbara G. Ryder, Sean Zhang:Interprocedural Modification Side Effect AnalysisWith Pointer Aliasing.
ポインタによるエイリアスを考慮した副作用解析.各代入文などで「ポインタが指しうる範囲」を調査することでどのメモリ領域が書き換えられるかを調べる.
アルゴリズムとしては,手続き単位で「到達しうるエイリアス」を集めておいて,手続き呼び出しごとにそのエイリアス集合を足していくという形になる.
Java などに応用する場合,多態性の管理が生じると少し大変そうだが.
_ 論文 ▲
Stuart M. Charters, Claire Knight, Nigel Thomas and Malcolm Munro:Visualisation for Informed Decision Making;From Code to Components.Proceedings of SEKE 2002, pp.765-772, July 15-19, Ischia, Italy.
ソフトウェアの可視化に関する論文で,ソフトウェアおよびコンポーネントをそれぞれ "City" として表現しようというもの.
建物が1個のメソッド(建物の高さがメソッドのコード量)でひとつの区画がクラスを表現して,クラスが集まって街が構成される,……とうようなSoftware City として表現するらしい.
また,コンポーネントについても,1つの建築物が1つ(あるいは複数の)コンポーネントで,数によって家だったりマンションだったり,といった表現を用いて,コンポーネントの機能ごとに街の区画整理を行うことで,コンポーネント群を表現する.
都市空間としての表現は実は強力なメタファらしいのだが,欠点として,非機能的特性(品質その他)はどう表現していいか困る,ということも挙げられている.
地理的な区分は,単純な階層区分よりは「境界のあたり」といった表現ができるので多少表現の範囲は広そうだが,構造が階層的であることに変わりはないので最初に何を基準に区画化するかが,大きな影響を与えそう.
2004-05-11 古い日記からの変換データ [長年日記] ▲
2004-05-12 古い日記からの変換データ [長年日記] ▲
2004-05-13 古い日記からの変換データ [長年日記] ▲
_ SPLAT ▲
忘れていたが,Workshop のサマリが出てた.
http://www.daimi.au.dk/~eernst/splat04/summary.html の Summary のところ.
2004-05-14 古い日記からの変換データ [長年日記] ▲
2004-05-17 古い日記からの変換データ [長年日記] ▲
2004-05-18 古い日記からの変換データ [長年日記] ▲
_ Eclipse ▲
コールグラフ構築を手抜きできないかなーと調べていたらCall Hierarchy Plugin なんてものがあるらしい.
@ITで紹介されていたのでちょっとびっくり.http://www.atmarkit.co.jp/fjava/javatips/009eclipse006.html
_ 論文 ▲
輪講で説明された論文.
Brian Demsky, Martin Rinard:Role-Based Exploration of Object-Oriented Programs.ICSE 2002.
オブジェクトの役割(Role)は「どのオブジェクトから参照されていて,どのオブジェクトを参照しているか」によって決まるだろう,という仮定に基づいて,動的解析の結果からRole の変化を見つけ,状態遷移図を構築する.
アイディアは面白い.類似したアプローチに,メソッド呼び出しの前後を仮に状態とみなして有限オートマトンを構築する,というものがあるが,こちらはオブジェクト間の関係を用いている.
同一のクラスでも,利用されているコンテキストによってRole が区別されることになるので,色々なクラスから利用されるタイプのライブラリ的なクラスを取り扱う場合に意味がありそう.
2004-05-19 古い日記からの変換データ [長年日記] ▲
2004-05-20 古い日記からの変換データ [長年日記] ▲
2004-05-21 古い日記からの変換データ [長年日記] ▲
_ 日記CGI ▲
ひそかにデータの XML 化を進めているが,やっぱり parse に時間がかかるのか,どうも遅い.インデクス情報を XML にしたのは失敗か.
先に計算可能な部分だけ事前にHTML化する,というのとインデクス情報は単なる行単位のテキストかRDB か何かにしたほうがよさそう.
_ Eclipse ▲
Kent Beck,Erich Gamma は Java Spider なんてものを作っているらしい.http://sourceforge.net/projects/javaspider/ Eclipse 用 update site があるので,そこからインストールできる.ドキュメントがないので plugin.xml を読むと,デバッグパースペクティブに機能を追加している. こんな感じ. デバッガで Variables (通常はウィンドウ右上の,変数情報を表示するエリア)のポップアップメニューに「Explore」という項目が増えていて,それを叩くと Spider View 上にぽつんと「JDILocalVariable」といった文字列が出現する.このオブジェクトがドラッグ&ドロップで移動でき,またクリックすると属性値などが表示される.で,属性となっているオブジェクトを表示させると矢印で接続されて,今まで見てきたオブジェクトの関係を忘れずに探索していくことができる. 利便性についての評価は現時点ではできそうもない.まだα版だし.ただ,面白いツールにはなりそうな気がする.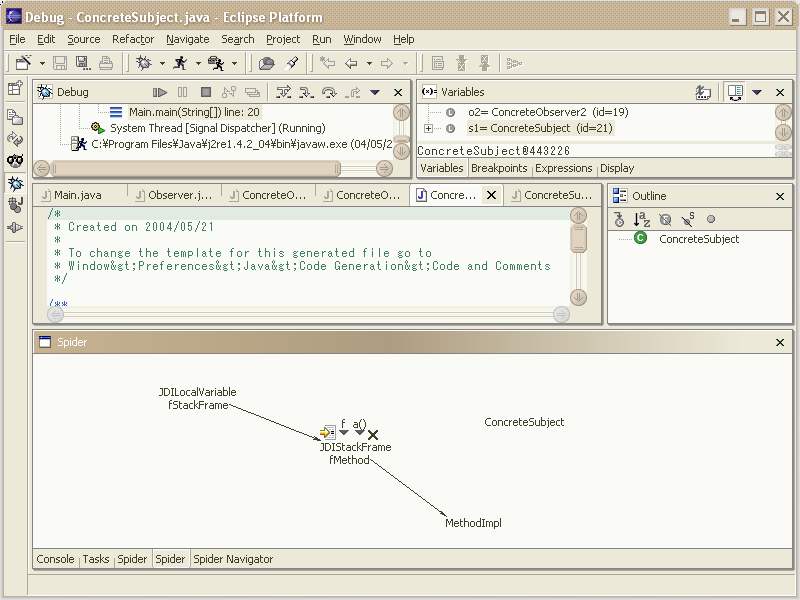{kind=link}
2004-05-26 古い日記からの変換データ [長年日記] ▲
_ 授業 ▲
院生相手のソフトウェア開発論にて,出張中の先生の代理で Eclipse の使い方を説明.主にはデバッガの使い方の紹介だが,1時間ほどかかった.
サンプルコードを,README.txt に合わせて修正するという課題を出してみた.問題は履修者が35人もいたこと.去年の倍くらい.M1の配属人数から考えて専攻の人数はそんなに多くないはずなので,去年よりも境界領域とかで履修者が増えたのか?採点が大変だ.
しかし,開発環境や周辺ツールをいろいろ使ってみる,というコンセプトの授業なので,課題を出さないとたぶん多くの学生は使おうとすらしないだろうし,その辺は難しいところ.授業で1回完結で何も提出させない,というのもアリかもしれないが,それだと授業中に答えさせるような形式にしないと駄目か.それはそれで準備が面倒.
2004-05-27 古い日記からの変換データ [長年日記] ▲
_ bun45 ▲
文学部サーバのFTPアカウント情報が学内便で届いた.さっそく bun45.let.osaka-u.ac.jp に ssh してそこから ftp する.bun45 への ssh も学内からでないと通らないので,外で作業するときは研究室のサーバにフォワードしてもらってbun45 にアクセスしにいくことになる.
色々作業した結果,ruby は読み込む lib がコンパイル時にPREFIX/lib に固定されるようなので,そこを再コンパイルしたバイナリを文学部サーバにはアップロードしておく必要があるらしいということが判明.ライブラリ読み込みで失敗してる可能性をちゃんと検討してみてよかった.
_ JET ▲
AspectJ ML で,AspectJ のコード生成とかするのにはどうしたらいいだろう,というところから紹介されていたJET (Java Emitter Templates) の Tutorial を読んでみた.http://www.eclipse.org/articles/Article-JET/jet_tutorial1.htmlhttp://www.eclipse.org/articles/Article-JET2/jet_tutorial2.html
JSP みたいなテンプレートをテキストファイル中に書き込んでおくと,そこがテンプレート展開される.Eclipse 上では,このファイルを編集すると,先頭行の <@ package="test" class=hoge >といったタグ情報で指定されたクラス名のJava クラスに自動変換されるらしい.あとは,生成された Template クラスに引数を渡せばテキストが出てくる,ということになる.
JET で生成される Template クラスはあくまでテンプレートのままなので,Java プロジェクト上で使用する Java ソースをいきなり生成する,というのとは違うので注意が必要.でも,ソース生成系のプラグインを作りたい場合には便利そう.
2004-05-28 古い日記からの変換データ [長年日記] ▲
_ Calendar ▲
hyCalendar に色付け機能を実装してみた.
|赤|赤く色づけされる|青|ここは青色になる改行で元の色に戻る
という感じの色名による記述をする.いちおうユーザが任意の文字列を設定できるようにはしたので|仕事|なんとかとか書いて "|仕事|" 以降を青の強調にする,とかいった記述はできるようになった.ポップアップ時は,今のところ,この装飾文字列が素で出てしまうのでオプションで消せるようにするかどうか検討する必要がある.消せるようにしようとすると,描画時だけにやっていた装飾文字列の parse を日付アイテム側に移動しないといけないので少し面倒ではあるが…….
また,ドキュメントを書くのも遅れているのでリリースは日曜あたりか週明けかになりそう.
2004-05-29 古い日記からの変換データ [長年日記] ▲
2004-05-30 古い日記からの変換データ [長年日記] ▲
_ Eclipse ▲
いまさら気づいたが,Eclipse のダイアログは,ときどき文章量のほうがダイアログサイズより多いので省略されてしまっている場合があるみたい.
Java ビルド・パスの追加における[変数の追加] は,実は[拡張...]を選んで変数が指しているフォルダから先のJAR ファイル選択をするのが正しい使い方らしい.(ラベルにメッセージが出ていたのだが, "..." で 省略されていて気づかなかった)
[外部 JAR の追加] はディレクトリによる絶対パスあるいはプロジェクト内部の相対パスによる追加で,ECLIPSE_HOME などの変数を使った可変クラスパスの追加は [変数の追加] らしい.なんか言葉の使い方としていけてないような気がする.変数というより「可変パスの追加」なのかもしれない.(.classpath ファイル中では,それぞれ kind="lib" と kind="var" として表記される)
_ JUnit ▲
授業で教える都合で,とりあえず勉強しながら使ってみる.何となく「達人プログラマー」やXP本で話は聞いているのでテストケースを作ってみる.
Eclipse から使うと,クラスを右クリックして[新規]-[その他...] [JUnit/TestCase] でそのクラスのテスト用クラスが生成される.すごく便利.[実行...] [JUnit] を選ぶと「パッケージ内のすべてのテストケースを実行」とか選べて,JUnit View からボタン1つでテスト実行した結果を見られる.これは,これから Java でコード書くときはJUnit 使っていこうかな,と思ってしまうくらい快適.さらっとテストケースと実装を書いてしまう.
いちおう学生にはテストケースを渡してコードを書いてみるとかやらせないといけないので,クラスのコードを抜いてかわりに // TODO タスク・タグを埋め込んだ状態にしておく.